
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- mme paper
- WGAN
- conjugate pseudo label paper
- CoMatch
- CGAN
- CycleGAN
- 백준 알고리즘
- cifar100-c
- mocov3
- dann paper
- simclrv2
- dcgan
- Pseudo Label
- UnderstandingDeepLearning
- 딥러닝손실함수
- shrinkmatch paper
- Meta Pseudo Labels
- 최린컴퓨터구조
- shrinkmatch
- semi supervised learnin 가정
- GAN
- adamatch paper
- Entropy Minimization
- Pix2Pix
- remixmatch paper
- BYOL
- tent paper
- 컴퓨터구조
- SSL
- ConMatch
- Today
- Total
Hello Data
VGGNet(2014) 구조 리뷰 본문
저번에 썼던 Lenet(1998)과 AlexNet(2012)에 이은 CNN 모델 구조이디.
2014년에 발표된 VGGNet(2014)이다.
Imagenet 분류 대회에서 92.7%를 기록하였으며 현재도 전이학습으로 많이 사용되는 모델이다.


기본 구조는 왼쪽과 같으며 층의 깊이에 따라 VGG-16, VGG-19 이렇게 나뉘어져있다.
기존 모델들과 비교해보면서 가장 쉽게 눈에 띄는 점은 일단 층의 깊이이다.
우측 이미지에서 AlexNet과 비교해보면 이 차이를 확실하게 느낄 수 있다.
이렇게 레이어를 깊게 쌓는다면 비선형성을 많이 더해질 수 있기 때문에 일정 깊이까지는 성능이 좋다.
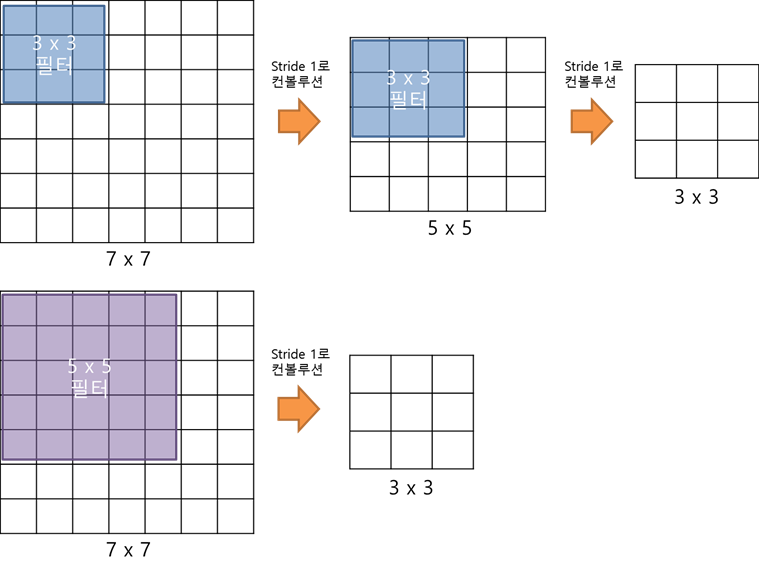

위 이미지와 같이 커널 크기를 5x5 -> 3x3으로 변경함으로써 output으로 나오는 이미지 결과는 같지만
그 과정에 있어서 비선형성을 더해줄 수 있다. 또한 작은 커널로 인해 효율적인 receptive field(수용영역)를 얻는다고 한다.
여기서 receptive field는 하나의 피쳐맵이 수용하는 크기인데 이는 커널 크기와 직접적으로 연관되있다고 한다.
직관적으로 input이미지에 대해 수용능력이 크면 좋을 것이라고 생각이 되기 때문에 더 큰 수용능력을 얻기위해
큰 커널을 사용할 수 있다.(아마 이러한 이유로 기존 모델들이 큰 커널 사이즈를 사용했나 싶다.)
그렇지만 단순히 커널 크기를 늘린다면 연산할 파라미터의 양이 늘어나기 때문에 좋은 방법이 아니라고 한다.
receptive field 에 대한 자세한 설명은 https://chacha95.github.io/2018-12-02-Deeplearning3/ 이 부분을 참고하였다.
다음은 VGG의 구조이다.
INPUT_SHAPE = (224,224,3)
vggnet = Sequential()
#블록1
vggnet.add(Conv2D(filters = 64, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same', input_shape = INPUT_SHAPE))
vggnet.add(Conv2D(filters = 64, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(MaxPool2D((2,2), strides = (2,2)))
#블록2
vggnet.add(Conv2D(filters = 128, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 128, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(MaxPool2D((2,2), strides = (2,2)))
#블록3
vggnet.add(Conv2D(filters = 256, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 256, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 256, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(MaxPool2D((2,2), strides = (2,2)))
#블록4
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(MaxPool2D((2,2), strides = (2,2)))
#블록5
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(Conv2D(filters = 512, kernel_size = (3,3), strides = (1,1), activation = 'relu',
padding = 'same'))
vggnet.add(MaxPool2D((2,2), strides = (2,2)))
#블록6 (분류기)
vggnet.add(Flatten())
vggnet.add(Dense(4096, activation = 'relu'))
vggnet.add(Dropout(0.5))
vggnet.add(Dense(4096, activation = 'relu'))
vggnet.add(Dropout(0.5))
vggnet.add(Dense(1000, activation = 'softmax'))
vggnet.summary()케라스로 작성하였으며 이전 AlexNet보다 층이 깊음을 알 수 있다.
그러나 여기서 단순히 층을 추가해 깊게 쌓는 것은 성능이 더 떨어졌다고 한다.
그리고
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 56, 56, 96) 34944
max_pooling2d (MaxPooling2D (None, 27, 27, 96) 0
)
batch_normalization (BatchN (None, 27, 27, 96) 384
ormalization)
conv2d_1 (Conv2D) (None, 27, 27, 256) 614656
max_pooling2d_1 (MaxPooling (None, 13, 13, 256) 0
2D)
batch_normalization_1 (Batc (None, 13, 13, 256) 1024
hNormalization)
conv2d_2 (Conv2D) (None, 13, 13, 384) 885120
conv2d_3 (Conv2D) (None, 13, 13, 384) 1327488
conv2d_4 (Conv2D) (None, 13, 13, 256) 884992
max_pooling2d_2 (MaxPooling (None, 6, 6, 256) 0
2D)
batch_normalization_2 (Batc (None, 6, 6, 256) 1024
hNormalization)
flatten (Flatten) (None, 9216) 0
dense (Dense) (None, 4096) 37752832
dropout (Dropout) (None, 4096) 0
dense_1 (Dense) (None, 4096) 16781312
dropout_1 (Dropout) (None, 4096) 0
dense_2 (Dense) (None, 10) 40970
=================================================================
Total params: 58,324,746
Trainable params: 58,323,530
Non-trainable params: 1,216
_________________________________________________________________총 파라미터 연산량은 5800만개이다.
전체적으로 구조는 AlexNet과 다른 점은 없지만 커널 사이즈를 일괄적으로 3x3으로 맞춰줌으로써
층의 깊이와 비선형성을 더해 성능이 좋아진 모습을 확인할 수 있다.
'딥러닝' 카테고리의 다른 글
| 비전공생의 Backpropagation(역전파) 직접 손으로 해보기 (0) | 2022.11.09 |
|---|---|
| 비전공생의 Gradient Descent(경사 하강법)살펴보기 (0) | 2022.11.09 |
| ResNet(2015) 구조 리뷰 (0) | 2022.10.25 |
| GoogleNet(2014) 구조 리뷰 (0) | 2022.10.23 |
| LeNet(1998), AlexNet(2012) 구조 리뷰 (0) | 2022.10.22 |



