
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- CoMatch
- SSL
- dann paper
- conjugate pseudo label paper
- simclrv2
- GAN
- 딥러닝손실함수
- CGAN
- adamatch paper
- BYOL
- 컴퓨터구조
- cifar100-c
- remixmatch paper
- CycleGAN
- 최린컴퓨터구조
- 백준 알고리즘
- shrinkmatch paper
- ConMatch
- mme paper
- shrinkmatch
- Pix2Pix
- mocov3
- WGAN
- dcgan
- Entropy Minimization
- UnderstandingDeepLearning
- semi supervised learnin 가정
- tent paper
- Pseudo Label
- Meta Pseudo Labels
- Today
- Total
Hello Data
비전공생의 Adversarial Learning for Semi supervised Semantic Segmentation(2018)논문 리뷰 본문
비전공생의 Adversarial Learning for Semi supervised Semantic Segmentation(2018)논문 리뷰
지웅쓰 2023. 6. 8. 18:54https://arxiv.org/pdf/1802.07934v2.pdf
SSL을 segmentation에 적용하고 싶어서 읽을 첫 논문이다. 시험기간인데 공부안하고 논문 읽어 버리기~
Introduction
FCN 방법과 추가적인 모듈은 semantic segmentation 에서 SOTA를 달성했지만, task 자체가 각 픽셀당 정확한 클래스로 분류해야 하므로 정확하고 많은 pixel annotation 데이터를 필요로 한다고 하며 이는 비용이 많이 든다. 따라서 이러한 문제를 해결하기 위해서 semi/weakly supervised method를 사용하는 것이 도움이 된다고 한다.
따라서 이 논문에서는 이 시기에 성공을 거둔 GAN을 활용하려는 시도를 한다. 기존의 GAN은 2개의 network로 이루어져있는데 generator는 noise vector를 입력으로 받고 discriminator를 속이기 위한 이미지를 생성하고 discriminator는 generator가 생성한 이미지를 가짜라고 할 수 있도록 훈련한다. 이러한 과정을 반복하면 discriminator가 잘 분간할 수 없도록 (50%) generator는 이미지를 생성할 수 있다. 그러나 여기 논문에서는 noise vector를 입력으로 받는 것이 아닌 이미지를 입력을 받고 이를 semantic labels로 생성한다. 이러한 과정을 통해 network는 GT값과 가까운 map을 생성한다. 그리고 discrminator는 생성한 map과 기존 GT map을 분간하는 훈련을 받는다.
이 논문의 contribution은 다음과 같다.
1. semantic segmentation을 향상시키기 위해 adversarial framework 도입
2. 추가적인 annotation없이 semi supervised framework 통해 성능 향상
3. discriminator 를 이용해 semi supervised 활용해 unlabeled image에 대해 segmentation 활용
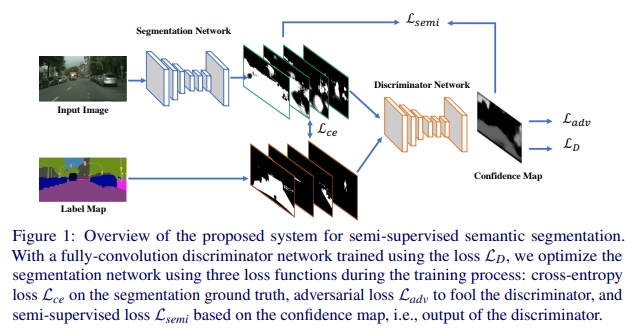
위는 논문에서 제시하는 구조이다. 훈련해야하는 network는 segmentation network이다.
Algorithm Overview
구조에서 Segmentation network는 task를 수행하는 어떤 네트워크여도 상관 없다. input (H x W x 3)을 받으면 probability map (H x W x C)를 뱉는다(여기서 C는 semantic categories). 그리고 discriminator network 는 probability map을 input으로 받고(그림으로 보면은 2개의 map을 다 받는 거 같다), confidence map( H x W x 1)을 내뱉는다. 각각의 픽셀들은 확률값을 나타내는데, 1에 가까울수록 GT값이라고 생각하는 것이며 0에 가까울수록 segmentation Network에서 내뱉은 값이라고 생각하는 것이다.
훈련과정에서 labeled 된 이미지와 unlabeld 된 이미지 둘 다 사용한다. labeled 된 이미지를 사용할 경우 GT값과의 비교를 통해 Cross entropy loss, Adversarial loss를 사용한다.그리고 저자들은 이 구조에서 discriminator network는 labeled 된 데이터가 들어올 때만 훈련을 수행한다고 한다(사용은 하지만 gradient가 흐르지 않는다는 말 같다). unlabeled 이미지를 사용할 경우, segmentation prediction을 얻은 후, discriminator network를 통해 confidence map을 생성하고 이를 masked cross entropy loss를 사용한다고 하는데, 이 부분은 아직 잘 이해가 안간다.
Semi supervised trainign with Adversarial network
baseline network로는 ImageNet, MSCOCO 로 pretrained 된 ResNet 101을 backbone으로 DeepLabv2를 사용했다고 한다. 마지막에는 classification layer를 사용하지 않았고, 마지막 CNN 2개의 layer의 stride는 1로 설정했다고 한다. 추가로 receptive field 를 크게하기 위해 dilated convolution을 사용했고, SPP를 사용했다.
discriminator network로는 https://arxiv.org/pdf/1511.06434.pdf (DCGAN)여기서 나온 network를 backbone으로 했다고 한다. 그리고 batch norm 같은 경우 batch size가 클 때만 효율적이기 때문에 사용하지 않았다.

discriminator의 손실함수는 위와 같다. S는 segmentation network, D는 discriminator network이다. yn 의 값이 1이면 GT에서 왔다는 것이다. D(S(X)) 는 confidence map을 의미한다. GT label map은 one-hot encoding으로 semantic categories에 맞게 변환이 된다(H x W x 1 -- > H x W x C). 한가지 발생할 수 있는 issue로는 discriminator가 너무 쉽게 어디서 왔는지 판별할 수 있는가 인데, 저자들이 이 연구에서는 나오지 않았다고 하며, 이에 대한 이유로는 Fully convolutional을 사용하였기 때문에 spatial difficulty를 늘렸다는 것이 저자들의 생각이다.

segmentation network의 손실함수는 위와 같이 수행된다.
먼저 labeled data가 들어왔을 때 loss 과정이다.

첫번째 Cross entropy loss는 위와 같은데, GT값인 Y와 S(X) 의 CE를 구함을 알 수 있다.

두번째 loss인 adversarial loss는 위와 같은데, D(S(X)) 를 통해 구해진다. 이건 segmentation loss이므로 최대한 1에 가깝게 만들어 discriminator를 혼란스럽도록 만들 것이다. 그러나 adversarial loss값을 결정하는 lamda값 같은 경우 작게 설정되는데 그 이유는 높을 경우 CE loss없이 over-correct 하는 결과가 나온다고 한다.

unlabeld data가 들어올 경우 수행되는 loss이다. T라는 threshhold값을 두고, I( D(S(X)) ) 값을 내보낸다. 그리고 Y hat 값에 대해서는 self-taught, one-encoded ground truth 값이라고 하는데, 이건 discriminator가 생성한 GT값이다. I는 indicator function이며 thresh hold 값을 넘기면1, 아니면 0을 내뱉는다. 여기서는 0.1~ 0.3을 두고 실험했다고 한다. 그렇다면 해당 loss는 각 channel마다 gt값을 비교하여, 최대한 gt값에 다가갈 수 있도록 훈련시키는 것이다.
Experimental Results
pytorch를 사용하고 SGD를 사용했다고 한다.
PASCAL VOC 2012, Cityscapes 데이터셋을 활용해 실험을 해보았다고 한다.
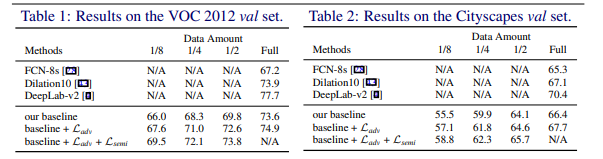
multi scale fusion없이 deeplab v2 와 비슷한 성능을 보인다고 한다.

adversarial loss, semi supervised loss를 더했을 때 결과가 깔끔한 것을 확인할 수 있다.
semi supervised loss가 직관적으로 이해가 되지는 않았는데 나중에 한번 더 볼 예정이다. 그리고 코드도 살펴봐야겠다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Pseudo label(2013)논문 리뷰 (0) | 2023.06.25 |
|---|---|
| 비전공생의 Mean teacher semi supervised learning (2018) 논문 리뷰 (0) | 2023.06.11 |
| 비전공생의 Medical Image Segmentation Using deep learning: Survey(2021) 논문 리뷰 (2) | 2023.06.06 |
| 비전공생의 SimMIM(2021)논문 리뷰 (0) | 2023.05.28 |
| 비전공생의 Segformer(2021) 논문 리뷰 (0) | 2023.05.25 |



