
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- shrinkmatch paper
- dann paper
- Entropy Minimization
- dcgan
- CycleGAN
- 최린컴퓨터구조
- remixmatch paper
- tent paper
- mocov3
- adamatch paper
- Pseudo Label
- BYOL
- Meta Pseudo Labels
- mme paper
- simclrv2
- GAN
- 백준 알고리즘
- cifar100-c
- ConMatch
- 딥러닝손실함수
- Pix2Pix
- semi supervised learnin 가정
- UnderstandingDeepLearning
- WGAN
- SSL
- 컴퓨터구조
- conjugate pseudo label paper
- CoMatch
- CGAN
- shrinkmatch
- Today
- Total
Hello Computer Vision
비전공생의 GAN(Generative Adversarial Nets, 2014) 코드 구현 본문
지난 번 논문 리뷰에 이어서 코드 구현을 해볼라고 한다.
https://keepgoingrunner.tistory.com/8
GAN(Generative Adversarial Nets, 2014) 논문 리뷰
GAN에 관심가진지 한 3달 정도가 지났고 논문에 대해서도 한번 겉핥기로 본 적이 있긴한데 앞으로 더 많은 논문을 볼텐데 GAN의 시초인 이 논문을 제대로 안 볼 수 없다고 생각하여 논문을 따로 복
keepgoingrunner.tistory.com
pytorch로 작성하였고 해당 데이터셋은 Fashion MNIST 를 사용하였다.
전체 코드는 해당 github에서 확인할 수 있습니다.
https://github.com/JiWoongCho1/Gernerative-Model_Paper_Review/blob/main/GAN.ipynb
GitHub - JiWoongCho1/Gernerative-Model_Paper_Review: 생성모델 논문 review 및 코드 구현입니다.
생성모델 논문 review 및 코드 구현입니다. Contribute to JiWoongCho1/Gernerative-Model_Paper_Review development by creating an account on GitHub.
github.com
1. 라이브러리
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import FashionMNIST
from torchvision.utils import make_grid
import imageio
import numpy as np
import matplotlib.pyplot as plt
2. 데이터셋 정의
transforms 를 활용하여 텐서로 변경, 정규화를 해준다.
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = FashionMNIST(root = './data', download = True, train = True, transform = transform)
trainloader = DataLoader(trainset, batch_size = 100, shuffle = True)3. Generator(생성자) 정의
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.n_features = 128
self.n_out = 784 # 28 x 28
self.linear = nn.Sequential(
nn.Linear(self.n_features, 256),
nn.LeakyReLU(0.2), #음수 구간 그래프가 y = 0.2 x
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.n_out),
nn.Tanh())
def forward(self, x):
x = self.linear(x)
x = x.view(-1, 1, 28, 28)
return xGenerator를 정의해준다.
벡터의 크기는 128이며, 활성화 함수는 LeakyReLU를 사용해준다.
여기서는 MLP를 사용해 28 x 28 이미지를 만들어준 모습이다.
4. Discriminator 정의
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.n_in = 784
self.n_out = 1
self.linear = nn.Sequential(
nn.Linear(self.n_in, 1024),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, self.n_out),
nn.Sigmoid())
def forward(self, x):
x = x.view(-1, 784)
x = self.linear(x)
return xDiscriminator를 정의해준다.
입력 이미지를 받고 MLP를 거쳐 마지막 출력은 sigmoid를 활용해준다.(확률 값)
5. 훈련시키기
generator = Generator()
discriminator = Discriminator()
g_optim = optim.Adam(generator.parameters(), lr = 2e-4) #최적화는 아담을 사용한다
d_optim = optim.Adam(discriminator.parameters(), lr = 2e-4)
g_losses = []
d_losses= []
images = []
criterion = nn.BCELoss() #이진분류 함수를 사용한다
def noise(n, n_features = 128): #크기가 batch_size, 128짜리의 랜덤 백터를 사용한다(평균0, 분산1)
data = torch.randn(n, n_features)
return data
def label_ones(size):
data = torch.ones(size, 1)
return data
def label_zeros(size):
data = torch.zeros(size, 1)
return data
최적화 함수는 Adam 을 사용해주고 손실함수는 진품, 모조품에 대해서 분류하는 것이니 이진분류를 사용해준다.
배치크기 x 벡터 크기만큼 벡터 생성하는 함수, 진품, 모조품에 대해서 라벨을 붙일 함수를 정의해준다.
def train_discriminator(optimizer, real_data, fake_data):
n = real_data.size(0)
optimizer.zero_grad()
prediction_real = discriminator(real_data)
d_loss = criterion(prediction_real, label_ones(n))
prediction_fake = discriminator(fake_data)
g_loss = criterion(prediction_fake, label_zeros(n))
loss = d_loss + g_loss
loss.backward()
optimizer.step()
return loss.item()Discriminator 훈련 함수이다.
1. real data(진품), fake data(모조품, G가 만든 것) 을 받는다.(여기서 n은 배치크기를 말한다)
2. real data는 1 라벨을 붙여 진짜이미지임을 훈련시키고 가짜데이터는 0 라벨을 붙여 훈련시킨다.
def train_generator(optimizer, fake_data):
n = fake_data.size(0)
optimizer.zero_grad()
prediction = discriminator(fake_data)
loss = criterion(prediction, label_ones(n))
loss.backward()
optimizer.step()
return loss.item()Generator 훈련 함수이다.
1. Discriminator 가 fake data에 대해 내린 판단에 대해 이를 1로 바꾸기 위해 노력한다.(진짜 이미지 만들도록 노력한다)
test_noise = noise(64)
l = len(trainloader)
for epoch in range(71):
g_loss = 0
d_loss = 0
for data in trainloader:
imgs, _ = data
n = len(imgs)
fake_data = generator(noise(n)).detach()
real_data = imgs
d_loss += train_discriminator(d_optim, real_data, fake_data)
fake_data =generator(noise(n))
g_loss += train_generator(g_optim, fake_data)
img = generator(test_noise).detach()
img = make_grid(img)
images.append(img)
g_losses.append(g_loss / l)
d_losses.append(d_loss / l)
if epoch % 10 == 0:
print(f'epoch : {epoch:.3f}, g_loss : {g_loss:.3f}, d_loss : {d_loss:.3f}')정의된 함수를 이용해 훈련시킨다.
pytorch는 따로 지정하지 않는다면 모든 gradient를 추적하기 때문에 Discriminator를 훈련할 때는
.detach()를 붙여준다.
6. 결과 살펴보기
to_image = transforms.ToPILImage()
imgs = [np.array(to_image(i)) for i in images]
imageio.mimsave('fashion_items1.gif', imgs)
plt.figure(figsize = (10,10))
plt.subplot(121)
plt.imshow(imgs[0])
plt.subplot(122)
plt.imshow(imgs[69])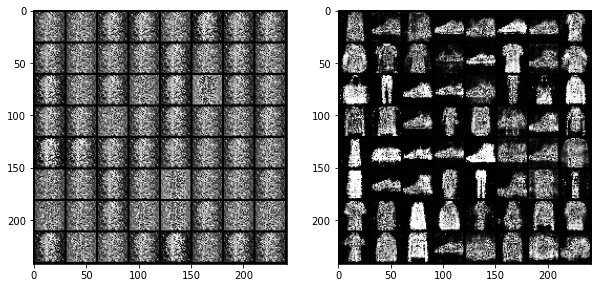
처음할 때는 노이즈들의 집합이었다면 마지막 쯤 되서는 형체를 알아볼 수 있도록 이미지를 갖추었음을 알 수 있다.
그러나 아쉬운 점은 FashionMNIST 데이터셋은 종류가 한정되어 있어 새로운 데이터를 생성하지 못한다는 단점이 있다.
(학습할 수 있는 분포가 다양하지 않기 때문에라고 생각한다.)
plt.figure(figsize = (20,10))
plt.plot(g_losses)
plt.plot(d_losses)
plt.legend(['Generator', 'Discriminator'])
plt.title('Loss')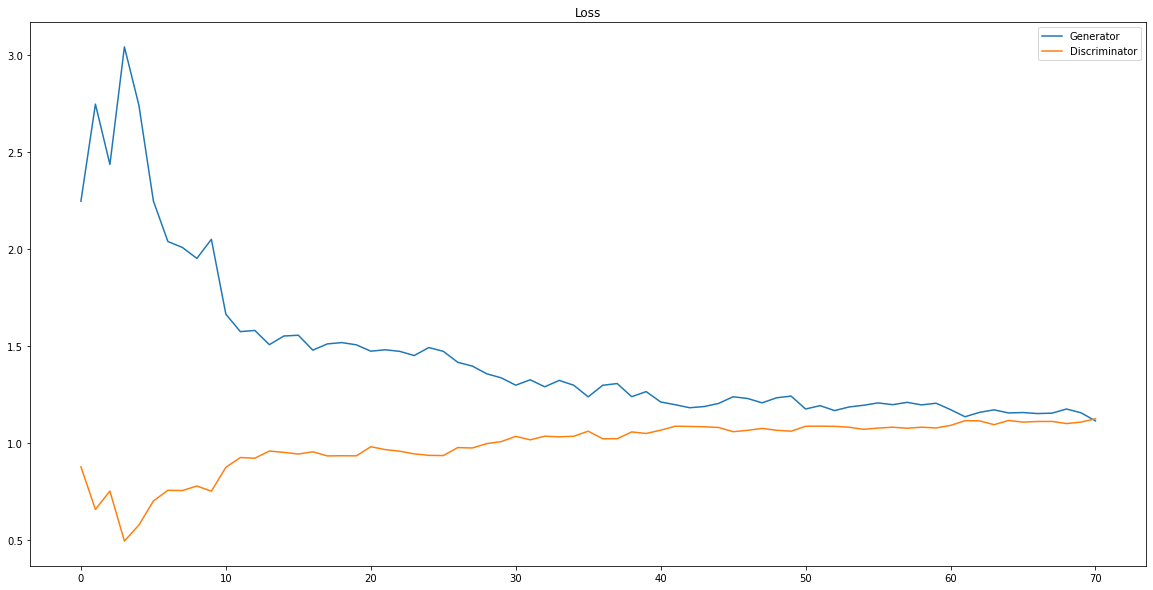
보면은 Generator의 loss 와 Discriminator의 loss가 잘 수렴했음을 알 수 있다.
이미지의 크기가 크지도 않고 흑백 데이터셋이었기 때문에 학습이 원활하게 잘 되지 않았나 쉽다.
(예를 들어 고화질의 얼굴 데이터셋을 사용했다면 Discriminator의 성능이 압도적으로 좋아서 Generator가 훈련을 하지
못하지 않았을 까 생각한다.)
틀린 점이나 잘못된 점 있다면 언제든 지적해주시면 감사하겠습니다.



