
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- shrinkmatch paper
- Meta Pseudo Labels
- WGAN
- 최린컴퓨터구조
- 백준 알고리즘
- SSL
- semi supervised learnin 가정
- UnderstandingDeepLearning
- simclrv2
- conjugate pseudo label paper
- adamatch paper
- cifar100-c
- Pseudo Label
- mocov3
- Entropy Minimization
- 컴퓨터구조
- remixmatch paper
- dcgan
- tent paper
- ConMatch
- GAN
- Pix2Pix
- BYOL
- CycleGAN
- CGAN
- shrinkmatch
- CoMatch
- mme paper
- 딥러닝손실함수
- dann paper
- Today
- Total
Hello Data
Introduction 본문
1-1. What is machine Learning?
컴퓨터 프로그램은 경험(E)을 통해 무언가의 태스크(T)를 학습하고 어느 정도의 성과(P)를 내게 되는데 T에 대한 성과 P를 E를 통해 향상시켜간다. 따라서 이 세상에는 T에 따른 많은 머신러닝 방법들이 있다. 여기서는 많은 종류의 ML을 커버하지만 probabilistic 관점(perspective)에서 다룬다.
이러한 관점으로 다루는 이유는 첫번째로 불확실성 속의 의사결정을 하는데 가장 최적의 접근이며 확률적 접근은 과학과 엔지니어링 분야에의 언어라고 할 수 있다.
1-2. Supervised learning
ML에서의 가장 흔한 방법은 supervised learning이다. T는 x -> y로 가는 매핑을 배우는 f를 배우는 것이다. 이 x는 features, covariate(공변량), predictors라고 불리며 흔히 fixed dimensional vector이다. y는 label, target, response 라고 불린다. 경험 E는 N개의 input-output pairs의 형태이며 training set 으로 불린다. P는 output형태에 따라 측정된다.
1-2-1. Classification
분류 문제에서 output space는 C개의 정렬되지 않은 클래스들의 공간이라고 할 수 있다. input이 주어졌을 때 class 를 예측하는 것은 pattern recognition이라고 주로 불린다(만약 label 이 {0,1}로 정의될 경우 이진 분류이다).
1-2-1-4. Empirical risk minimization
지도학습의 목적이라고 하면 분류 모델로 하여금 어떠한 input이 들어왔을 때 label을 신뢰도있게 예측하는 것이다. 이러한 성능을 예측하는 흔한 방법은 훈련 데이터에 대해 misclassification rate를 측정하는 것이다.

여기서 I는 indicator function인데 조건이 True면 1, False면 0을 내뱉는다. 여기서는 모든 에러는 같다고 보고 있지만 사실 어떤 경우에는 어떤 에러가 다른 경우보다 더 심각할 수 있다. 그럴 경우 우리는 empirical risk라는 것을 훈련 데이터의 평균 손실 값을 정의할 수 있다.

문제에 대한 모델을 맞추고 훈련시키는 것은 empirical risk를 최소화하는parameter들을 찾는 것인데 다음과 같이 나타낼 수 있다.

여기서 theta 는 손실값을 최소로 만드는 파라미터 집합이라고 할 수 있는데 이를 empirical risk minimization이라고 한다. 그러나 우리의 목적은 훈련 데이터에 대해서만 잘하는 것이 아니라 아직 보지 못한 future data에 대한 기대 손실값을 최소화 하는 것인데 이를 generalize한다고 한다.
1-2-1-5. Uncertainty
많은 경우에 우리는 input에 대하여 완벽하게 예측하고 정확한 결과 값을 낼 수 없을 것인데 그 이유는 input-output mapping에 대하여 지식이 부족하기 때문인데 이를 epistemic uncertainty/ model uncertainty 라고 한다. 다양한 분야에서 우리의 예측값에 대하여 uncertainty 를 나타내는 것은 매우 중요하다. 따라서 우리는 information gathering action을 수행해야 한다. 그리고 우리는 uncertainty 를 conditional probability distribution을 이용해 캐치할 수 있다.
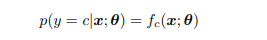
여기서 $f_{c}$ 는 [0,1]사이에 있고 C개의 클래스에 대한 합은 1이 되어야 한다. 그러나 이러한 제약들을 피하기 위해 모델로 하여금 log probabilities를 내뱉도록 하는 것이 흔히 있다. 그리고 이러한 확률을 softmax function에 넣어 확률을 구한다. softmax 에 대한 input는 $ a = f(x;\theta )$ 로 정의한다면 이는 logits라고 부른다. 따라서 이는 다음과 같이 나타낼 수 있다.

여기서 f를 affine function이라고 하는데 해당 함수는 다음과 같이 나타낼 수 있다.

여기서 (b, w)는 모델의 파라미터라고 할 수 있고 이러한 모델을 logistic regression이라고 부른다. w는 regression coefficients 라고 부르고 ML에서는 weights라고 부른다.
1-2-1-6. Maximum likelihood estimation
우리가 흔히 확률적 모델을 만들 때 negative log probability 를 우리의 손실 함수로 사용하는 것은 흔하다.
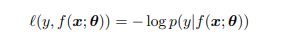
이는 5장에서 설명되지만 직관적으로 보자면 좋은 모델은 input x에 대해 올바른 output y를 부여하는 것이다. 훈련 데이터에 대해 average negative log probability 는 다음과 같이 정의된다.
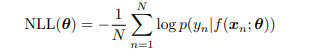
이것을 negative log likelihood라고 부르고 이것을 최소화할 수 있다면, 우리는 maximum likelihood estimate(MLE)를 계산할 수 있다. 이는 데이터를 모델에 맞출 때 사용하는 아주 흔한 방법이다.
1-2-2. Regression
우리가 y를 예측할 때 실수 범위에서의 y를 예측하고 싶다면 이는 regression이라고 한다. 회귀는 분류와 매우 비슷하지만 output으로 하여금 실수가 나와야 하므로 다른 손실 함수를 사용한다. 가장 흔히 사용하는 함수는 quadratic loss, 즉 l2 loss인데 다음과 같이 정의된다.

이는 오차에 대한 작은 값보다 큰 값에 대하여 더 많은 페널티를 준다. 이를 mean squared error, 즉 MSE 라고 한다.

우리는 모델의 uncertatinty 역시 모델링 해야하는데 회귀문제에서는 output distribution을 Gaussian / Normal 분포로 예측하는 것이 흔하다.

우리는 input을 통해 mean을 계산할 수 있고 조건부 확률 분포를 얻을 수 있다.

1-2-2-1. Linear regression
우리는 데이터를 simple linear regression을 통하여 맞출 수 있는데 이는 다음과 같다.

여기서 w를 기울기, b는 offset인데 이를 조정함으로서 MSE 를 줄일 수 있다.
1-2-2-2. Polynomial regression
조금 전에 설명한 것은 데이터에 아주 좋지는 않은데 우리는 이를 D차원의 polynomial regression을 사용하여 향상시킬 수 있다.

quadratic shape은 linear model보다는 더 나아보인다.
1-2-3. Overfitting and generalization
앞서 언급한 empirical risk는 다음과 같이 쓸 수 있다.
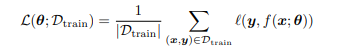
여기서 $|D_{train} | $ 은 훈련데이터셋의 크기를 나타낸다. 우리는 suitable flexible 모델을 사용한다면 training loss를 0으로 만들 수 있는데 이는 각각의 input에 대해 correct output을 기억하면 되는 것이다. 그러나 우리가 진정으로 원하는 것은 new data에 대한 정확도를 올리는 것이다. 모델이 훈련데이터에 대해 완벽하게 맞고 충분히 복잡하다면 이는 overfitting이다 라고 말할 수 있다. 모델이 overfitting인지 알기위해서는 알 수 없지만 True distribution 을 p*(x,y)라고 가정할 수 있는데 이를 empirical risk를 측정하는 것이 아니라 population risk를 측정하는 것이다.
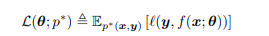
그리고 empirical risk와 population risk의 gap을 generalization gap이라고 하는데 만약 이 gap이 크다면(low empirical risk, high population risk) 이것은 overfitting 된 것이다. 결과적으로 우리는 p* 분포를 알 수 없지만 우리는 데이터를 2가지로 분리할 수 있고 이를 test set이라고 부른다. 따라서 우리는 population risk를 이 test risk에 근사해서 사용할 수 있다. 실제로 우리는 test set뿐만 아니라 validation set을 추가해서 사용한다. 참고로 test set은 모델을 fitting 할 때 사용하는 것이 아닌 model을 selection할 때 사용된다.
1-2-4. No free lunch theorem
우리는 당연하게도 가장 좋은 것을 선택하고 싶지만 아쉽게도 어떠한 문제에도 가장 좋은 best model은 없다. 따라서 이를 no free lunch theorem이라고 한다. 이러한 것에 대한 하나의 이유는 set of assumptions(inductive bias)가 하나의 domain 에서는 잘 맞을 수 있지만 다른 것에는 poor한 성능을 내기 때문이라는 것이다. 따라서 많은 모델을 알고 알고리즘 기술을 하는 것이 중요하다.
1-3. Unsupervised learning
지도학습의 관점에서 x는 y와 pair쌍이고 이것의 목표는 mapping하는 것이다. 이것은 유용하지만 필수적으로 지도학습은 "glorified curve fitting" 이다(직역하면 미화된 커브 피팅인데 아마 오버피팅과 비슷한 뜻을 가지는 거 같습니다). 흥미로운 것은 데이터에 대해 mapping을 하는 것이 아니라 이해하는 것인데 즉, input 에 대해 y없이 훈련하는 것이다. 이를 Unsupervised learning이라고 한다. 확률적인 관점에서 비지도학습은 p(y|x) 가 아닌 p(x), 무조건적인 모델을 학습하는 것인데 이는 새로운 데이터 x를 생성할 수 있다. unsupervised learning은 labeled dataset가 필요없으며, category를 나누도록 배울 필요가 없다. unsupervised learning은 모델로 하여금 high dimensional input에 대해 설명하도록 할 수 있다.
1-3-2. Discovering latent "factors of variation"
높은 차원의 데이터를 다루다보면은 저차원의 공간으로 근사시키는 것이 유용하며 데이터의 본질(essence)를 얻을 수 있다. 이러한 방법에 대해 하나의 접근 방식은 각각의 고차원의 데이터는 저차원의 latent factors에 의해 생성되었다는 가정이다. 이를 표기화 해본다면 z -> x (z: low, x: high).
1-3-3. Self supervised learning
unsupervised learning의 최신 접근은 self supervised learning이다. 이를 위해서 우리는 unlabeled 데이터로 하여금 proxy supervised task를 정의한다. 이를 표기해본다면 $x_{1} = f(x_{2}, \theta)$, x2를 데이터로 한다면 x1이 output으로 나오도록 훈련하는 것이다.
1-5-3. Preprocessing discrete input data
많은 ML 모델들은 데이터가 실수 집합의 벡터로 이루어졌다고 가정한다. 그러나 가끔 데이터는 discrete input features를 가질 수 있는데, categorical 변수들이 예시이다.
1-5-3-1. One-hot encoding
우리가 categorical features를 가질 때(e.g.성별, 성) 우리는 그 데이터들을 수로 만드는 것이 필요하다. 이를 수행하기 위한 가장 표준 방법은 one-hot encoding을 하는 것이다. 이를 표기하면 다음과 같다. $one-hot(x) = [I(x = 1), I(x = 2), ... I(x = k)]$
1-5-3-2. Feature crosses
위와 같이 categorical 변수들을 one-hot encoding했을 때 linear model은 main effects를 잡아낼 수 있지만 interaction effect를 잡아낼 수는 없다. 예를 들어 연료 효율성을 알기 위해 2개의 categorical 변수가 있다 하면 x1은 차 종류, x2를 회사 나라로 해보자. 그러면 $\theta(x) = [1, I(x1 = S), I(x1 = T), I(x2 = U), I(x2 = J)] $로 나타낼 수 있는데, 해당 모델은 2개의 feature사이에서의 의존성을 잡아낼 수 없다. 예를 들어 우리는 트럭이 연료효율이 적다고 예측할 수 있지만 어쩌면은 미국 트럭이 일본 트럭보다 효율이 낮을수도 있는 이것을 linear model에서는 caputre 할 수 없다는 것이다. 이를 해결하기 위해서는 우리는 feature crosses를 계산해보면 된다.

여기까지가 1강의 내용이었고 NLP쪽 내용이나 강화학습 내용은 제가 제외하였습니다. 첫장이라서 가벼운 설명들만 있었지만 재밌는 내용들이 많아서 좋았습니다.
'머신러닝' 카테고리의 다른 글
| Probability: Univariate Models (1) | 2023.09.11 |
|---|---|
| 머신 러닝 공부 (0) | 2023.09.09 |
| batch size 와 mini-batch size의 차이점 (0) | 2023.04.11 |
| [머신러닝] XGBoost 에 대한 이해 (0) | 2023.02.14 |
| [머신러닝] Gradient Boost 공부해보기 (GBM) (0) | 2023.02.05 |

