
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 컴퓨터구조
- WGAN
- CycleGAN
- Meta Pseudo Labels
- Pix2Pix
- simclrv2
- mme paper
- ConMatch
- mocov3
- CGAN
- shrinkmatch
- tent paper
- dann paper
- Pseudo Label
- dcgan
- cifar100-c
- 백준 알고리즘
- 딥러닝손실함수
- BYOL
- conjugate pseudo label paper
- GAN
- CoMatch
- Entropy Minimization
- remixmatch paper
- UnderstandingDeepLearning
- SSL
- 최린컴퓨터구조
- semi supervised learnin 가정
- shrinkmatch paper
- adamatch paper
- Today
- Total
목록Self,Semi-supervised learning (53)
Hello Computer Vision
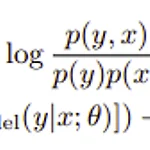 ReMixMatch(2020) 논문리뷰
ReMixMatch(2020) 논문리뷰
논문의 풀 제목은 ReMixMatch: Semi supervised learning with distribution alignment and augmentation anchoring 이다.https://arxiv.org/pdf/1911.09785.pdf2020년에 나온 논문이고 Distribution alignment를 사용하는데 이를 사용하는 이유를 잘 살펴볼 필요가 있는 논문이다. IntroductionSSL에서는 주로 consistency regularization, entropy minimiation이 활용되는데 여기서 entropy minimization은 high confidence prediction을 내뱉도록 모델을 훈련시키는 것이다. 그리고 큰 framework 자체는 기존의 mixmat..
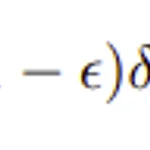 Label smoothing 효과 공부해보기
Label smoothing 효과 공부해보기
Label smoothing은 구글에서 낸 Classification model인 Inception model에서 먼저 제안되었다. https://arxiv.org/pdf/1512.00567.pdf 그리고 Label smoothing이 왜 좋고, 어떤 점이 좋은지에 대한 논문은 https://arxiv.org/pdf/1906.02629.pdf 그래서 기존 논문에서는 main contribution은 아니지만 regularization 방식으로 소개되는데 이 논문에서 소개된 내용만큼과 효과에 대하여 간단하게 적어보려고 한다. K개의 class 가 있다고 하면은 model이 계산한 각각의 class 에 대한 probability는 $$ p(k | x) = \frac{exp(z_{k})}{\sum^{K}_{k..
 SelfMatch(2021) 논문리뷰
SelfMatch(2021) 논문리뷰
이번에 semi를 공부하는 도중에 self 와 섞인 논문을 발견하여 리뷰해보려고 한다. NIPS에 억셉된 시기는 2020년으로 해당 년도는 SimCLR이 나오고 FixMatch가 나온지 얼마 안된 시점인데 두가지를 결합한 것이 큰 novelty라고 생각했다. https://arxiv.org/pdf/2101.06480.pdf Introductionsemi supervised learning은 적은 수의 라벨에 대해서 문제를 해결할 수 있는 매력적인 방법이고 self supervised 역시 SimCLR 로 시작된 contrastive learning을 활용한 representation learning을 한 후 fine tuning을 하면은 좋은 성능을 냈다고 한다. 따라서 논문은 이 두가지 방법을 활용해..
 Semi Supervised Learning에서 Pseudo label의 정확성
Semi Supervised Learning에서 Pseudo label의 정확성
여러 Semi Supervised Learning(SSL) 논문을 읽으면서 느꼈던 점은 "Softmax를 사용하는데 잘못된 클래스로 오분류하고 이 값이 threshold값을 넘으면 계속 오류가 나고 성능이 안좋아지지 않을까? " 라는 생각을 했고 이를 실험해봐야겠다는 생각을 했다. 기본 세팅은 FixMatch에 있는 세팅을 따랐고, Unlabeled 데이터에 대한 argmax softmax 값이 Threshold에 넘든 말든 얼마나 많이 오분류를 하는지 한번 살펴보았다. acc_list = [] #correct_list = [] for i in range(epochs): start = time.time() labeled_iter = iter(labeled_trainloader) unlabeled_iter..
이번에 semi-supervised learning 을 공부함에 있어 사용되는 방법들을 조금 더 원론적으로 알아보려고한다. (해당 내용은 Kevin.P.Murphy 의 Probabilistic Machine Learning에 있는 내용을 따랐습니다) Semi supervised learning에서는 unlabeled데이터가 주로 사용된다. 따라서 우선 Pseudo label이라는 기법이 많이 사용된다. 해당 기법은 unlabeled데이터에 대하여 pseudo prediction 을 생성하는 기법이라고 할 수 있다. 물론 이 과정에서 confirmation bias가 생성될 수 있는데 이러한 bias에 대해서는 threshold가 많이 사용된다(이것도 문제가 많다고 생각). 2024.02.14 수정) 단순..
 비전공생의 Whitening for Self-Supervised Representation Learning(2021) 논문리뷰
비전공생의 Whitening for Self-Supervised Representation Learning(2021) 논문리뷰
해당 논문은 ICLR 2021 에 억셉된 논문으로 기존의 Contrastive loss 대신 쓸 수 있는 loss를 제시하는 논문이다. https://arxiv.org/pdf/2007.06346.pdf Introduction 최근의 Self-Supervised learning(SSL) 의 성공에 대해서 언급하면서 이에 대한 단점도 언급한다. Contrastive learning을 수행하려면 많은 수의 negative 데이터들이 필요하거나, 2개의 네트워크를 사용하는 등의 여러가지 방법들이 고안되어왔다. 저자는 따라서 새로운 SSL loss function을 제시한다(물론 기본적으로 증강을 통한 invariance 특징을 사용하는 것은 동일하다). 이 논문에서는 whitening transformation..
 비전공생의 FreeMatch(2023) 논문리뷰
비전공생의 FreeMatch(2023) 논문리뷰
2023 ICLR에 억셉된 논문이고 풀 제목은 FreeMatch: Self-Adaptive Thresholding for Semi-Supervised Learning이다. Flexmatch, AdaMatch의 후속 논문이라고보면 된다. https://arxiv.org/pdf/2205.07246v3.pdf Introduction 최근 SSL은 pseudo label, consistency regularization으로 이루어진다. 그러나 이러한 fixed threshold, ad-hoc threshold adjusting(Dash 논문에서는 t에 따라 threshold를 변경하지만 learning status 를 반영하지 않는다)은 많은 unlabeled 데이터를 훈련초기에 사용할 수 없을 것이며, cla..
 비전공생의 FlexMatch(2021) 논문리뷰
비전공생의 FlexMatch(2021) 논문리뷰
해당 논문은 NIPS 2021년에 억셉된 논문이고 풀 제목은 FlexMatch: Boosting semi-Supervised Learning with Curriculum Pseudo labeling이다. FixMatch에서 사용된 fix threshold에 대하여 adpative 하게 바꿔주는 것이 특징이다. https://arxiv.org/pdf/2110.08263.pdf Introduction SSL 에서 자주 사용되는 기법은 pseudo labeling과 consistency regularization이고 FixMatch는 이러한 방법을 사용해 SOTA를 달성했다. 그러나 threshold를 fix시키는 방법은 학습 초기 단계에서 많은 unlabeled 데이터를 반영할 수 없다고 한다. 따라서 이 ..